Statistic Lecture Nasional Pojok Statistik Unisba Bahas Strategi Tepat Memilih Metode Klasifikasi Machine Learning
METRO BANDUNG, bandungpos.id – Pojok Statistik Universitas Islam Bandung (Unisba) kembali menggelar Statistics Lecture sebagai bagian dari komitmen memperkuat literasi statistik di tengah pesatnya perkembangan teknologi berbasis data. Kegiatan bertajuk “Smart Modeling in Machine Learning: Strategi Pemilihan Metode Klasifikasi yang Tepat” ini dilaksanakan secara daring pada Sabtu (28/2/2026).
Agenda ilmiah ini menjadi ruang pembelajaran strategis bagi akademisi dan praktisi dalam memahami pemodelan cerdas (smart modeling) di bidang machine learning, khususnya pada metode klasifikasi data.
Sebanyak 111 peserta tercatat mengikuti kegiatan ini. Mereka berasal dari berbagai perguruan tinggi di Indonesia, antara lain Politeknik Statistika STIS, Institut Teknologi Sepuluh Nopember, Universitas Negeri Makassar, Institut Teknologi Sumatera, serta Universitas Sulawesi Barat, dan sejumlah perguruan tinggi lainnya.
Selain kalangan akademisi, peserta juga berasal dari berbagai instansi seperti Badan Pusat Statistik, Dinas Komunikasi Informatika, Statistik dan Persandian, Dinas Tenaga Kerja dan Transmigrasi, hingga masyarakat umum yang memiliki minat pada analisis dan pengolahan data.
Hadir sebagai narasumber, Dr. Asrirawan, M.Si., dosen Program Studi Statistika Universitas Sulawesi Barat, menyampaikan materi secara komprehensif mengenai konsep dasar machine learning, dengan penekanan pada metode klasifikasi. Kegiatan dipandu oleh Dila Nurrahmah selaku Agen Pojok Statistik Unisba.
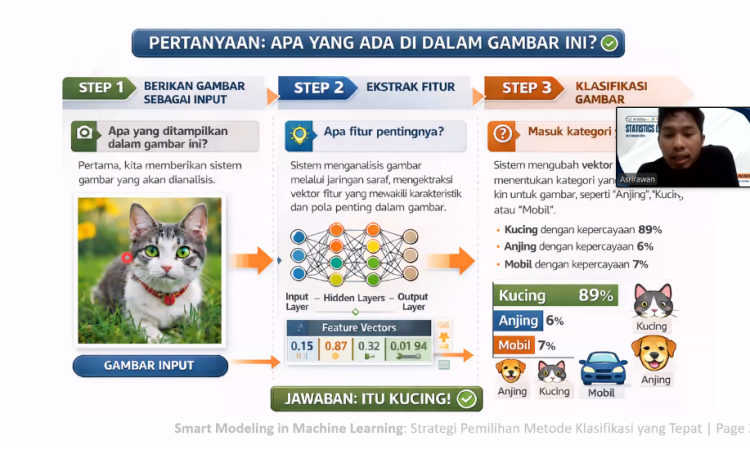
Dalam paparannya, Dr. Asrirawan menjelaskan tahapan klasifikasi yang mencakup proses input data, ekstraksi fitur, hingga proses klasifikasi untuk menghasilkan prediksi. Ia juga memperkenalkan beberapa jenis klasifikasi yang umum digunakan dalam analisis data, yakni Binary classification, Multiclass classification, Multilabel classification.
Ketiga pendekatan tersebut memiliki fungsi dan penerapan yang berbeda sesuai dengan kebutuhan serta karakteristik data yang dianalisis.
Algoritma Klasifikasi dan Faktor Penentu Keberhasilan Model
Tak hanya membahas teori, narasumber juga menguraikan berbagai algoritma klasifikasi populer dalam machine learning, seperti Logistic Regression, K-Nearest Neighbors (KNN), Decision Tree, Support Vector Machine (SVM), Naive Bayes, dan Random Forest.
Menurutnya, performa model tidak semata ditentukan oleh algoritma yang digunakan. Faktor lain seperti kualitas data, proses pembersihan (data cleaning), pemilihan hyperparameter, serta kemampuan menangani persoalan overfitting, underfitting, dan imbalanced data turut berperan penting.
Penggunaan metode evaluasi yang tepat, misalnya melalui confusion matrix, juga menjadi aspek krusial dalam memastikan model yang dibangun memiliki tingkat akurasi dan reliabilitas yang optimal.
Antusiasme peserta terlihat dari sesi diskusi yang berlangsung interaktif. Berbagai pertanyaan diajukan terkait implementasi machine learning, strategi menentukan algoritma klasifikasi yang paling sesuai, hingga tantangan teknis dalam proses klasifikasi data.
Melalui kegiatan ini, Pojok Statistik Unisba berharap peserta mampu meningkatkan pemahaman tentang strategi pemilihan metode klasifikasi dalam machine learning, memperkuat literasi statistik, serta mengembangkan kompetensi analisis data guna menghadapi era teknologi yang semakin berbasis data.(askur)***






{kind=link}